Save your hard earned metrics wins with Metrics On-Call
About the author
Jeff Chang (@JeffChang30) is a growth technical leader at Pinterest and angel investor. If your startup is looking for an angel investor who can help with all things growth, please send over an email!
Intro
Developing an effective metrics on-call is key to maintaining a high rate of growth.
If you’ve been doing growth for a while, you may be familiar with the situation where you discover that one of your growth features has been broken for months, leading to a significant cumulative loss. There are several reasons why this happens. The most common reason is that the drop wasn’t noticed due to low visibility. Another common reason is that when the drop occurred, the team was unable to determine the root cause. Developing an effective metrics on-call is key to maintaining a high rate of growth. Without one, breakages are likely occurring and canceling out your major wins. This post is a follow up to Growth Monitoring Done Right, which I would recommend you read first. The previous post talks about the tools you need, whereas this post will focus on processes.
Metrics On-call
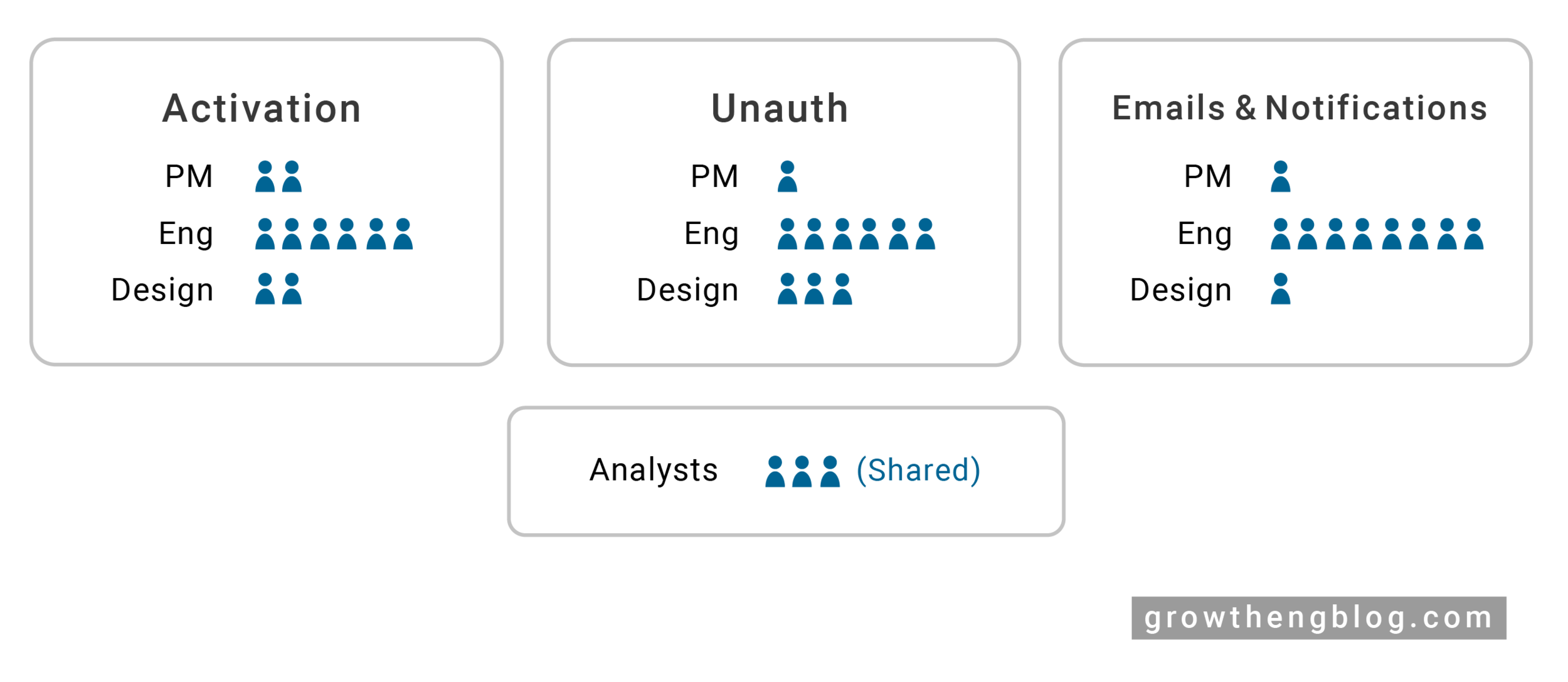
Having a great metrics on-call is key to maintaining a high rate of growth. In a nutshell, metrics on-call is a rotating schedule of people responsible for detecting, investigating, and resolving drops in key user metrics. On-call rotations are a common process that pretty much every technology company has, but a metrics on-call has a few differences.
One big difference is that usually, on-call responsibilities revolve around maintaining service uptime, but metrics on-call revolves around maintaining key user metrics in addition to service uptime. For example, when traffic drops, it could be due to several reasons. It could be due to a bad commit where a bug causes the page to be missing content. It could be due to a service failure that causes pages to serve HTTP 500’s. It could be due to a Google algorithm change. It could be something out of anybody’s control like a holiday.
Regular on-call sample health metrics:
success rate
cpu load
page load times
Metrics on-call sample health metrics:
iphone signups
push notification sends
onboarding completion rate
Benefits
A metrics on-call can end up taking a lot of time during bad weeks, but there are many benefits to having one. The first and most obvious one is maintaining a high growth rate. As you continue to improve your growth by adding on more and more growth features, it becomes harder to maintain them all. Also, as your company grows and more code changes occur, metrics-affecting bugs are more likely to occur. Unit and integration tests are common methods to reduce bugs, but on a fast-paced growth team, it’s hard for tests to match the pace of feature development. Metrics on-call will catch the bugs that significantly impact metrics and resolve them.
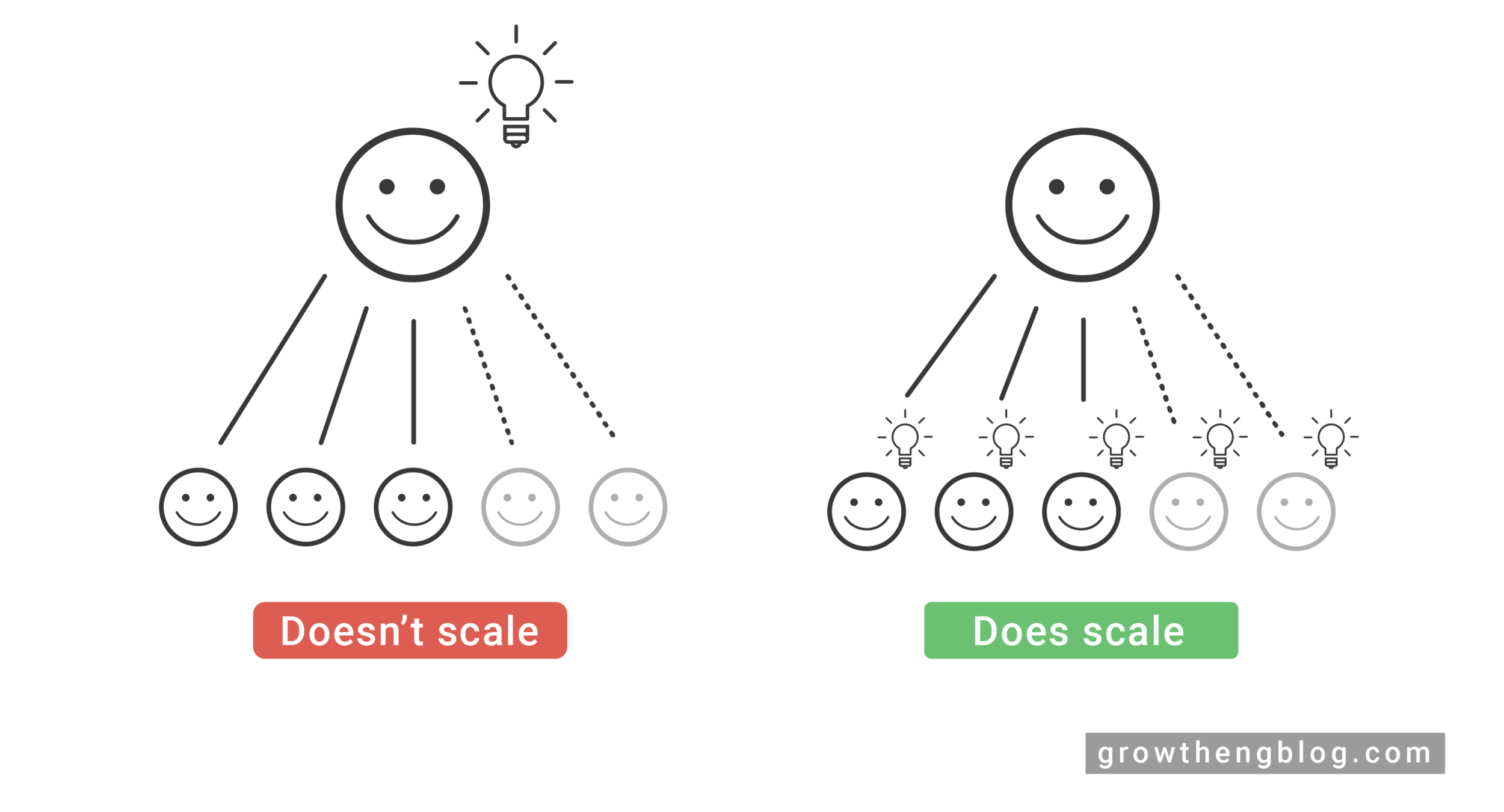
Another big benefit of a metrics on-call is team education of the company’s growth system. New growth team members who start doing on-call quickly learn which metrics are important to the growth of the company and what kind of internal and external changes can affect these metrics. This builds intuition on how to improve the company’s growth system and also is a source to find new growth opportunities.
Finally, metrics on-call builds a sense of ownership across the team. In a lot of early growth teams, usually only a few people are responsible for metrics health. It’s much better if the whole team is constantly being a guardian of the growth metrics since more issues will be caught and resolved faster. In addition, it reduces reliance on a few people to keep a growth rate high, which may be an issue for smaller growth teams.
Documentation
Good documentation is key to running a successful growth on-call system. Here are the things you should have in your metrics on-call documentation:
Responsibilities - Make it clear what the responsibility of the on-caller is and isn’t
It’s the responsibility of the on-caller to detect and drive metrics incident to resolution, whether it be pushing the fix themselves or making sure someone does
They are not responsible for actually fixing the issue if the issue was caused by another team, but are responsible for holding that team accountable
They are responsible for improving the monitoring system if needed, for example, fine tuning noisy alerts
Links to graphs - As your team’s visibility tools improve and more graphs get made, it’s important to add them to the documentation so people know where to find them
Escalation Process - For example, when should the on-caller file an incident ticket? When should they bring in more people to help investigate? Who should be aware of which situations and when?
Incident resolution tips - Especially helpful for beginners, who will be the main consumer of the metrics on-call documentation. For example:
Go through the user experience to reproduce a bug that causes the metrics to decline, then the root cause is usually easily found by doing a git bisect
Try to line up the metrics decline with a code change. If it is on a deploy time, then it is likely caused by an internal code change. Otherwise, it is likely an external dependency or service failure.
Looking into deeper segments is a big clue to the root cause. For example, if there is a signup drop, look into which platforms and referrers are affected by the drop.
Best Practices
Put new engineers on-call as soon as possible, with a mentor
The best way for new engineers to learn how to resolve metrics incidents is experience, so it’s best to get them started early
This also lowers the burden of metrics on-call for the rest of the team members quickly
Have a central chat room to discuss metrics incidents
This promotes visibility of ongoing incidents since team leads are in the channel and can follow along
Having multiple threads of different incidents reduces visibility
Update the chat room status with the current on caller so people know who they can bring up issues to
Do postmortems for metrics incidents even if internal service failure is not the root cause
Some incidents will be caused by the growth team and some will not. It’s important to see what improvements can be made even if incidents have external causes
Some common followups are improving graphs/alerting and improving processes
Schedule war rooms if the root cause is not figured out after a few hours of investigation by the on-caller
Some issues are very complex and require domain-specific knowledge to debug. This is the normal path of escalation so issues don’t stay unresolved for too long
Conclusion
As soon as you ship a few successful growth features and have a few members on your growth team, invest in a metrics on-call. These days, it’s important for companies to show a sustained rate of high growth. In order to maintain this high growth, shipping new features is not enough. You also have to make sure all the features and optimizations you shipped in order to get the current growth rate to work as intended. Metrics on-call is that safety net that makes sure mishaps don’t chip away at your hard earned growth rate.
Want to chat about building a high impact growth team? Email me at jeff@growthengblog.com
Building a high impact growth team